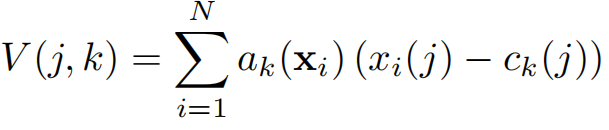??Redis 是一個基于內存的高性能 key-value 數據庫。是完全開源免費的,用C語言編寫的,遵守BSD協議。
??Redis 特點:
??字符串 string 是 Redis 最簡單的數據結構。Redis 所有的數據結構都是以唯一的 key 字符串作為名稱,然后通過這個唯一 key 值來獲取相應的 value 數據。不同類型的數據結構的差異就在于 value 的結構不一樣。Redis 的 string 可以包含任何數據,比如 jpg圖片或者序列化的對象(java 中對象序列化函數 serialize)
??內部實現,其本質是一個byte數組
struct sdshdr { long len; //buf數組的長度 long free; //buf數組中剩余可用字節數 char buf[]; //存儲實際字符串內容
}
??String 采用預分配冗余空間的方式來減少內存的頻繁分配,內部為當前字符串實際分配的空間 capacity 一般要高于實際字符串長度 len。當字符串長度小于 1M 時,擴容都是加倍現有的空間,如果超過 1M,擴容時一次只會多擴 1M 的空間。需要注意的是字符串最大長度為 512M。
鍵值對
> set name codehole
OK
> get name
"codehole"
> exists name
(integer) 1
> del name
(integer) 1
> get name
(nil)
批量鍵值對
??可以批量對多個字符串進行讀寫,節省網絡耗時開銷
> set name1 codehole
OK
> set name2 holycoder
OK
> mget name1 name2 name3 # 返回一個列表
1) "codehole"
2) "holycoder"
3) (nil)
> mset name1 boy name2 girl name3 unknow
> mget name1 name2 name3
1) "boy"
2) "girl"
3) "unknown"
過期和 set 命令擴展
??可以對 key 設置過期時間,到點自動刪除,這個功能常用來控制緩存的失效時間。不過這個 [自動刪除] 的機制是比較復雜的。
> set name codehole
> get name
"codehole"
> expire name 5 # 5s 后過期
... # wait for 5s
> get name
(nil)
> setex name 5 codehole # 5s 后過期,等價于 set + expire
> get name
"codehole"
... # wait for 5s
> get name
(nil)
> setnx name codehole # set 和 expire 原子執行,因為 name 不存在就執行創建成功
(integer) 1
> get name
"codehole"
> setnx name holycoder # set 和 expire 原子執行,因為 name 存在 set 創建不成功
(integer) 0
> get name
"codehole"
計數
??如果 value 值是一個整數,還可以對它進行自增操作。自增是有范圍的,它的范圍是 signed long 的最大最小值,超過了這個值,Redis 會報錯。
> set age 30
OK
> incr age
(integer) 31
> incrby age 5
(integer) 36
> incrby age -5
(integer) 31
set codehole 9223372036854775807
# Long.Max
Ok
??字符串是由多個字節組成,每個字節又是由 8 個 bit 組成,如此便可以將一個字符串看成很多 bit 的組合,這便是 bitmap「位圖」數據結構
??Redis 的列表相當于 Java 語言里面的 LinkedList,注意它是鏈表而不是數組,而且是雙向鏈表。這意味著 list 的插入和刪除操作非常快,時間復雜度為 O(1),但是索引定位很慢,時間復雜度為
O(n),這點讓人非常意外。
??當列表彈出了最后一個元素之后,該數據結構自動被刪除,內存被回收。
??Redis 的列表結構常用來做異步隊列使用。將需要延后處理的任務結構體序列化成字符
串塞進 Redis 的列表,另一個線程從這個列表中輪詢數據進行處理。
右邊進左邊出:隊列
> rpush books python java golang
(integer) 3
> llen books
(integer) 3
> lpop books
"python"
> lpop books
"java"
> lpop books
"golang"
> lpop books
(nil)
右邊進右邊出:棧
> rpush books python java golang
(integer) 3
> rpop books
"golang"
> rpop books
"java"
> rpop books
"python"
> rpop books
(nil)
慢操作
??lindex 相當于 java 鏈表的 get(int index)方法,它需要對鏈表進行遍歷,性能隨著參數 index 增大而變差。ltrim 和字面上的含義不太一樣,個人覺得它叫 lretain(保留) 更適合一些,因為 ltrim 跟兩個參數 start_index 和 end_index 定義了一個區間,在這個區間內的值,ltrim 是要保留,區間之外統統砍掉。我們可以通過 ltrim 來實現一個定長的鏈表,這一點非常有用。index 可以為負數,index=-1 表示倒數第一個元素,同樣 index=-2 表示倒數第二個元素。
> rpush books python java golang
(integer) 3
> lindex books 1 # O(n) 慎用,并不會刪除 "java"
"java"
> lrange books 1 -1 # 獲取從1開始到最后一個元素,O(n) 慎用, 并不會刪除
1) "python"
2) "java"
3) "golang"
> ltrim books 1 -1 # O(n) 慎用
OK
> lrange books 0 -1 # 獲取所有元素
1) "java"
2) "golang"
> ltrim books 1 0 # 這其實是清空了整個列表,因為區間范圍長度為負
OK
> llen books
(integer) 0
hash的底層存儲有兩種數據結構
??hash 結構也可以用來存儲用戶信息,不同于字符串一次性需要全部序列化整個對象,hash 以對用戶結構中的每個字段單獨存儲。這樣當我們需要獲取用戶信息時可以進行部分獲取。而以整個符串的形式去保存用戶信息的話就只能一次性全部讀取,這樣就會比較浪費網絡流量。
??hash 也有缺點,hash 結構的存儲消耗要高于單個字符串,到底該使用 hash 還是字符串,需要根據實際情況再三權衡。

??上圖中可以看到,當數據量比較小的時候,我們會將所有的key及value都當成一個元素,順序的存入到ziplist中,構成有序。
字典結構定義
typedef struct dict {// 類型特定函數dictType *type;// 私有數據void *privdata;// 哈希表,兩個元素dictht ht[2]// rehash時記錄的索引下標,當沒有rehash時,值為-1int rehashidx;} dict;
其中,哈希表dictht 的結構定義為:
typedef struct dictht {// 哈希表數組dictEntry **table;// 哈希表大小unsigned long size;// 哈希表大小掩碼,用于計算索引值unsigned long sizenask;// 該哈希表已有節點的數量unsigned long uesd;} dictht;
圖示結構如下

??Redis 的字典相當于 Java 語言里面的 HashMap,它是無序字典。內部實現結構上同 Java 的 HashMap 也是一致的,同樣的數組 + 鏈表二維結構。第一維 hash 的數組位置碰撞時,就會將碰撞的元素使用鏈表串接起來。
??不同的是,Redis 的字典的值只能是字符串,另外它們 rehash 的方式不一樣,因為Java 的 HashMap 在字典很大時,rehash 是個耗時的操作,需要一次性全部 rehash。Redis為了高性能,不能堵塞服務,所以采用了漸進式 rehash 策略。

??漸進式 rehash 會在 rehash 的同時,保留新舊兩個 hash 結構,查詢時會同時查詢兩個 hash 結構,然后在后續的定時任務中以及 hash 的子指令中,循序漸進地將舊 hash 的內容一點點遷移到新的 hash 結構中。
??當 hash 移除了最后一個元素之后,該數據結構自動被刪除,內存被回收。
??漸進式 rehash 的好處在于它采取分而治之的方式, 將 rehash 鍵值對所需的計算工作均灘到對字典的每個添加、刪除、查找和更新操作上, 從而避免了集中式 rehash 而帶來的龐大計算量。
> hset books java "thinks in java" # books 是 key,Java 是 hash中的 key # 如果 字符串包含空格 要用引號括起來
(integer) 1
> hset books golang "concurrency in go"
(integer) 1
> hgetall books # entries(),key 和 value 間隔出現
1) "java"
2) "thinks in java"
3) "golang"
4) "concurrency in go"
> hlen books
(integer) 2
> hget books golang
"concurrency in go"
> hset books golang "learning go programming" # 因為是更新操作,所以返回 0
(integer) 0
> hget books golang
"learning go programming"
> hmset books java "effective java" golang "modern golang
programming" # 批量 set
OK
??同字符串一樣,hash 結構中的單個子 key 也可以進行計數,它對應的指令是 hincrby,和 incr 使用基本一樣。
> hincrby user-laoqian age 1
(integer) 30
??set 是一個無序的、自動去重的集合數據類型,Set 底層用兩種數據結構存儲
??當集合中最后一個元素移除之后,數據結構自動刪除,內存被回收。 set 結構可以用來存儲活動中獎的用戶 ID,因為有去重功能,可以保證同一個用戶不會中獎兩次。
typedef struct intset {// 編碼類型uint32_t encoding;// 集合包含的元素數量uint32_t length;// 保存元素的數組int8_t contents[];
} intset;
> sadd books python
(integer) 1
> sadd books python # 重復
(integer) 0
> sadd books golang
(integer) 1
> smembers books # 注意順序,和插入的并不一致,因為 set 是無序的
1) "golang"
2) "python"
> sismember books python # 查詢某個 value 是否存在,相當于 contains(o)
(integer) 1
> sismember books rust
(integer) 0
> scard books # 獲取長度相當于 count()
(integer) 2
> spop books # 彈出一個
"python"
??zset 可能是 Redis 提供的最為特色的數據結構,它也是在面試中面試官最愛問的數據結構。zset為有序(有限score排序,score相同則元素字典排序),自動去重的集合數據類型,其底層實現為 字典(dict) + 跳表(skiplist),當數據比較少的時候用 ziplist 編碼結構存儲。

??zset 中最后一個 value 被移除后,數據結構自動刪除,內存被回收。 zset 可以用來存粉絲列表,value 值是粉絲的用戶 ID,score 是關注時間。我們可以對粉絲列表按關注時間進行排序。
??zset 還可以用來存儲學生的成績,value 值是學生的 ID,score 是他的考試成績。我們可以對成績按分數進行排序就可以得到他的名次。
> zadd books 9.0 "think in java"
(integer) 1
> zadd books 8.9 "java concurrency"
(integer) 1
> zadd books 8.6 "java cookbook"
(integer) 1
> zrange books 0 -1 # 按 score 排序列出,參數區間為排名范圍
1) "java cookbook"
2) "java concurrency"
3) "think in java"
> zrevrange books 0 -1 # 按 score 逆序列出,參數區間為排名范圍
1) "think in java"
2) "java concurrency"
3) "java cookbook"
> zcard books # 相當于 count()
(integer) 3
> zscore books "java concurrency" # 獲取指定 value 的 score
"8.9000000000000004" # 內部 score 使用 double 類型進行存儲,所以存在小數點精度問題
> zrank books "java concurrency" # 排名
(integer) 1
> zrangebyscore books 0 8.91 # 根據分值區間遍歷 zset
1) "java cookbook"
2) "java concurrency"
> zrangebyscore books -inf 8.91 withscores # 根據分值區間 (-∞, 8.91] 遍歷 zset,同時返回分值。inf 代表 infinite,無窮大的意思。
1) "java cookbook"
2) "8.5999999999999996"
3) "java concurrency"
4) "8.9000000000000004"
> zrem books "java concurrency" # 刪除 value
(integer) 1
> zrange books 0 -1
1) "java cookbook"
2) "think in java"
關于數據結構詳細請看這篇文章:redis 數據結構
??Redis 所有的數據結構都可以設置過期時間,時間一到,就會自動刪除。你可以想象 Redis 內部有一個死神,時刻盯著所有設置了過期時間的 key,壽命一到就會立即收割。

??你還可以進一步站在死神的角度思考,會不會因為同一時間太多的 key 過期,以至于忙不過來。同時因為 Redis 是單線程的,收割的時間也會占用線程的處理時間,如果收割的太過于繁忙,會不會導致線上讀寫指令出現卡頓。在過期這件事上,Redis 非常小心。
??redis 會將每個設置了過期時間的 key 放入到一個獨立的字典中,以后會定時遍歷這個字典來刪除到期的 key。除了定時遍歷之外,它還會使用惰性策略來刪除過期的 key,所謂惰性策略就是在客戶端訪問這個 key 的時候,redis 對 key 的過期時間進行檢查,如果過期了就立即刪除。定時刪除是集中處理,惰性刪除是零散處理。
??Redis 默認會每秒進行十次過期掃描,過期掃描不會遍歷過期字典中所有的 key,而是
采用了一種簡單的貪心策略。
??同時,為了保證過期掃描不會出現循環過度,導致線程卡死現象,算法還增加了掃描時間的上限,默認不會超過 25ms。
??設想一個大型的 Redis 實例中所有的 key 在同一時間過期了,會出現怎樣的結果?
??毫無疑問,Redis 會持續掃描過期字典 (循環多次),直到過期字典中過期的 key 變得稀疏,才會停止 (循環次數明顯下降)。這就會導致這期間線上讀寫 QPS 下降明顯。還有另外一種原因是內存管理器需要頻繁回收內存頁,這也會產生一定的 CPU 消耗。
??這里解析一下,假如單臺 Redis 讀寫請求 QPS 是 10w,也就是每個請求需要 0.00001s 來完成,每秒執行十次過期掃描,每次過期掃描都達到上限 25ms,那么每秒過期掃描總花費 0.25s,相當于 QPS 降低了 2.5W。
??所以業務開發人員一定要注意過期時間,如果有大批量的 key 過期,要給過期時間設置一個隨機范圍,而不能全部在同一時間過期。
# 在目標過期時間上增加一天的隨機時間
redis.expire_at(key, random.randint(86400) + expire_ts)
??從庫不會進行過期掃描,從庫對過期的處理是被動的。主庫在 key 到期時,會在 AOF 文件里增加一條 del 指令,同步到所有的從庫,從庫通過執行這條 del 指令來刪除過期的 key。
??因為指令同步是異步進行的,所以主庫過期的 key 的 del 指令沒有及時同步到從庫的話,會出現主從數據的不一致,主庫沒有的數據在從庫里還存在。
??Redis 數據庫可以通過配置文件來配置最大緩存,當寫入的數據發現沒有足夠的內存可用的時候,Redis 會觸發內存淘汰機制。Redis 為了滿足多樣化場景,提供了八種策略,可以在 redis.config 文件中配置。
??Redis 的數據全部在內存里,如果突然宕機,數據就會全部丟失,因此必須有一種機制來保證 Redis 的數據不會因為故障而丟失,這種機制就是 Redis 的持久化機制。
??Redis 的持久化機制有兩種,第一種是快照,第二種是 AOF 日志。快照是一次全量備份,AOF 日志是連續的增量備份。快照是內存數據的二進制序列化形式,在存儲上非常緊湊,而 AOF 日志記錄的是內存數據修改的指令記錄文本。AOF 日志在長期的運行過程中會變的無比龐大,數據庫重啟時需要加載 AOF 日志進行指令重放,這個時間就會無比漫長。所以需要定期進行 AOF 重寫,給 AOF 日志進行瘦身。

??我們知道 Redis 是單線程程序,這個線程要同時負責多個客戶端套接字的并發讀寫操作和內存數據結構的邏輯讀寫。
??在服務線上請求的同時,Redis 還需要進行內存快照,內存快照要求 Redis 必須進行文件 IO 操作,可文件 IO 操作是不能使用多路復用 API。
??這意味著單線程同時在服務線上的請求還要進行文件 IO 操作,文件 IO 操作會嚴重拖垮服務器請求的性能。還有個重要的問題是為了不阻塞線上的業務,就需要邊持久化邊響應客戶端請求。持久化的同時,內存數據結構還在改變,比如一個大型的 hash 字典正在持久化,結果一個請求過來把它給刪掉了,還沒持久化完呢,這尼瑪要怎么搞?
??那該怎么辦呢?
??Redis 使用操作系統的多進程 COW(Copy On Write) 機制來實現快照持久化,這個機制很有意思,也很少人知道。多進程 COW 也是鑒定程序員知識廣度的一個重要指標。
??Redis 在持久化時會調用 glibc 的函數 fork 產生一個子進程,快照持久化完全交給子進程來處理,父進程繼續處理客戶端請求。子進程剛剛產生時,它和父進程共享內存里面的代碼段和數據段。這是 Linux 操作系統的機制,為了節約內存資源,所以盡可能讓它們共享起來。在進程分離的一瞬間,內存的增長幾乎沒有明顯變化。
??子進程做數據持久化,它不會修改現有的內存數據結構,它只是對數據結構進行遍歷讀取,然后序列化寫到磁盤中。但是父進程不一樣,它必須持續服務客戶端請求,然后對內存數據結構進行不間斷的修改。
??這個時候就會使用操作系統的 COW 機制來進行數據段頁面的分離。數據段是由很多操作系統的頁面組合而成,當父進程對其中一個頁面的數據進行修改時,會將被共享的頁面復制一份分離出來,然后對這個復制的頁面進行修改。這時子進程相應的頁面是沒有變化的,還是進程產生時那一瞬間的數據。

??隨著父進程修改操作的持續進行,越來越多的共享頁面被分離出來,內存就會持續增長。但是也不會超過原有數據內存的 2 倍大小。另外一個 Redis 實例里冷數據占的比例往往是比較高的,所以很少會出現所有的頁面都會被分離,被分離的往往只有其中一部分頁面。每個頁面的大小只有 4K,一個 Redis 實例里面一般都會有成千上萬的頁面。
??子進程因為數據沒有變化,它能看到的內存里的數據在進程產生的一瞬間就凝固了,再也不會改變,這也是為什么 Redis 的持久化叫「快照」的原因。接下來子進程就可以非常安心的遍歷數據了進行序列化寫磁盤了。
??AOF 日志存儲的是 Redis 服務器的順序指令序列,AOF 日志只記錄對內存進行修改的指令記錄。
??假設 AOF 日志記錄了自 Redis 實例創建以來所有的修改性指令序列,那么就可以通過對一個空的 Redis 實例順序執行所有的指令,也就是「重放」,來恢復 Redis 當前實例的內存數據結構的狀態。
??Redis 會在收到客戶端修改指令后,先進行參數校驗,如果沒問題,就立即將該指令存儲到 AOF 日志緩存中,AOF 日志緩存 copy 到 內核緩存,但還沒有刷到磁盤,也就是先寫日志,然后再執行指令。這樣即使遇到突發宕機,已經存儲到 AOF 日志的指令進行重放一下就可以恢復到宕機前的狀態。
??Redis 在長期運行的過程中,AOF 的日志會越變越長。如果實例宕機重啟,重放整個AOF 日志會非常耗時,導致長時間 Redis 無法對外提供服務。所以需要對 AOF 日志瘦身。
??Redis 提供了 bgrewriteaof 指令用于對 AOF 日志進行瘦身。其原理就是開辟一個子進程對內存進行遍歷轉換成一系列 Redis 的操作指令,序列化到一個新的 AOF 日志文件中。序列化完畢后再將操作期間發生的增量 AOF 日志追加到這個新的 AOF 日志文件中,追加完畢后就立即替代舊的 AOF 日志文件了,瘦身工作就完成了。
??AOF 日志是以文件的形式存在的,當程序對 AOF 日志文件進行寫操作時,實際上是將內容寫到了內核為文件描述符分配的一個內存緩存中 OS buffer,然后內核會異步將臟數據刷回到磁盤的。
??這就意味著如果機器突然宕機,AOF 日志內容可能還沒有來得及完全刷到磁盤中,這個時候就會出現日志丟失。那該怎么辦?
??Linux 的 glibc 提供了 fsync(int fd)函數可以將指定文件的內容強制從內核緩存刷到磁盤。只要 Redis 進程實時調用 fsync 函數就可以保證 aof 日志不丟失。但是 fsync 是一個磁盤 IO 操作,它很慢!如果 Redis 執行一條指令就要 fsync 一次,那么 Redis 高性能的地位就不保了。
??所以在生產環境的服務器中,Redis 通常是每隔 1s 左右執行一次 fsync 操作,周期 1s是可以配置的。這是在數據安全性和性能之間做了一個折中,在保持高性能的同時,盡可能使得數據少丟失。
??Redis 同樣也提供了另外兩種策略,一個是永不 fsync——讓操作系統來決定合適同步磁盤,很不安全,另一個是來一個指令就 fsync 一次——非常慢。但是在生產環境基本不會使用,了解一下即可。
??快照是通過開啟子進程的方式進行的,它是一個比較耗資源的操作。
??所以通常 Redis 的主節點是不會進行持久化操作,持久化操作主要在從節點進行。從節點是備份節點,沒有來自客戶端請求的壓力,它的操作系統資源往往比較充沛。
??但是如果出現網絡分區,從節點長期連不上主節點,就會出現數據不一致的問題,特別是在網絡分區出現的情況下又不小心主節點宕機了,那么數據就會丟失,所以在生產環境要做好實時監控工作,保證網絡暢通或者能快速修復。另外還應該再增加一個從節點以降低網絡分區的概率,只要有一個從節點數據同步正常,數據也就不會輕易丟失。
??重啟 Redis 時,我們很少使用 rdb 來恢復內存狀態,因為會丟失大量數據。我們通常使用 AOF 日志重放,但是重放 AOF 日志性能相對 rdb 來說要慢很多,這樣在 Redis 實例很大的情況下,啟動需要花費很長的時間。
??Redis 4.0 為了解決這個問題,帶來了一個新的持久化選項——混合持久化。將 rdb 文件的內容和增量的 AOF 日志文件存在一起。這里的 AOF 日志不再是全量的日志,而是自持久化開始到持久化結束的這段時間發生的增量 AOF 日志,通常這部分 AOF 日志很小。

??于是在 Redis 重啟的時候,可以先加載 rdb 的內容,然后再重放增量 AOF 日志就可以完全替代之前的 AOF 全量文件重放,重啟效率因此大幅得到提升。
??目前我們講的 Redis 還只是主從方案,最終一致性。讀者們可思考過,如果主節點凌晨 3 點突發宕機怎么辦?就坐等運維從床上爬起來,然后手工進行從主切換,再通知所有的程序把地址統統改一遍重新上線么?毫無疑問,這樣的人工運維效率太低,事故發生時估計得至少 1 個小時才能緩過來。如果是一個大型公司,這樣的事故足以上新聞了。
??所以我們必須有一個高可用方案來抵抗單點故障,當故障發生時可以自動進行從主切換,程序可以不用重啟,運維可以繼續睡大覺,仿佛什么事也沒發生一樣。Redis 官方提供了這樣一種方案 —— Redis Sentinel(哨兵)。

??我們可以將 Redis Sentinel 集群看成是一個 ZooKeeper 集群,它是集群高可用的心臟,它一般是由 3~5 個節點組成,這樣掛了個別節點集群還可以正常運轉。
??它負責持續監控主從節點的健康,當主節點掛掉時,自動選擇一個最優的從節點切換為主節點。客戶端來連接集群時,會首先連接 sentinel,通過 sentinel 來查詢主節點的地址,然后再去連接主節點進行數據交互。當主節點發生故障時,客戶端會重新向 sentinel 要地址,sentinel 會將最新的主節點地址告訴客戶端。如此應用程序將無需重啟即可自動完成節點切換。比如上圖的主節點掛掉后,集群將可能自動調整為下圖所示結構。

??從這張圖中我們能看到主節點掛掉了,原先的主從復制也斷開了,客戶端和損壞的主節點也斷開了。從節點被提升為新的主節點,其它從節點開始和新的主節點建立復制關系。客戶端通過新的主節點繼續進行交互。Sentinel 會持續監控已經掛掉了主節點,待它恢復后,集群會調整為下面這張圖。

??此時原先掛掉的主節點現在變成了從節點,從新的主節點那里建立復制關系。
??Redis 主從采用異步復制,意味著當主節點掛掉時,從節點可能沒有收到全部的同步消息,這部分未同步的消息就丟失了。如果主從延遲特別大,那么丟失的數據就可能會特別多。Sentinel 無法保證消息完全不丟失,但是也盡可能保證消息少丟失。它有兩個參數可以限制主從延遲過大。
min-slaves-to-write 1
min-slaves-max-lag 10
??第一個參數表示主節點必須至少有一個從節點在進行正常復制,否則就停止對外寫請求,喪失可用性。
??何為正常復制,何為異常復制?這個就是由第二個參數控制的,它的單位是秒,表示如果 10s 沒有收到從節點的反饋,就意味著從節點同步不正常,是謂異常復制。
??接下來我們看看客戶端如何使用 sentinel,標準的流程應該是客戶端可以通過 sentinel 發現主從節點的地址,然后在通過這些地址建立相應的連接來進行數據存取操作。我們來看看 Python 客戶端是如何做的。
>>> from redis.sentinel import Sentinel
>>> sentinel = Sentinel([('localhost', 26379)], socket_timeout=0.1)
>>> sentinel.discover_master('mymaster')
('127.0.0.1', 6379)
>>> sentinel.discover_slaves('mymaster')
[('127.0.0.1', 6380)]
??sentinel 的默認端口是 26379,不同于 Redis 的默認端口 6379,通過 sentinel 對象的 discover_xxx 方法可以發現主從地址,主地址只有一個,從地址可以有多個。
>>> master = sentinel.master_for('mymaster', socket_timeout=0.1)
>>> slave = sentinel.slave_for('mymaster', socket_timeout=0.1)
>>> master.set('foo', 'bar')
>>> slave.get('foo')
'bar'
??通過 xxx_for 方法可以從連接池中拿出一個連接來使用,因為從地址有多個,redis 客戶端對從地址采用輪詢方案,也就是 RoundRobin 輪著來。
??有個問題是,但 sentinel 進行主從切換時,客戶端如何知道地址變更了 ? 通過分析源碼,我發現 redis-py 在建立連接的時候進行了主庫地址變更判斷。
??連接池建立新連接時,會去查詢主庫地址,然后跟內存中的主庫地址進行比對,如果變更了,就斷開所有連接,重新使用新地址建立新連接。如果是舊的主庫掛掉了,那么所有正在使用的連接都會被關閉,然后在重連時就會用上新地址。
??但是這樣還不夠,如果是 sentinel 主動進行主從切換,主庫并沒有掛掉,而之前的主庫連接已經建立了在使用了,沒有新連接需要建立,那這個連接是不是一致切換不了?
??繼續深入研究源碼,我發現 redis-py 在另外一個點也做了控制。那就是在處理命令的時候捕獲了一個特殊的異常 ReadOnlyError,在這個異常里將所有的舊連接全部關閉了,后續指令就會進行重連。
??主從切換后,之前的主庫被降級到從庫,所有的修改性的指令都會拋出 ReadonlyError。如果沒有修改性指令,雖然連接不會得到切換,但是數據不會被破壞,所以即使不切換也沒關系。

??RedisCluster 是 Redis 的親兒子,它是 Redis 作者自己提供的 Redis 集群化方案。
??相對于 Codis 的不同,它是去中心化的,如圖所示,該集群有三個 Redis 節點組成,每個節點負責整個集群的一部分數據,每個節點負責的數據多少可能不一樣。這三個節點相互連接組成一個對等的集群,它們之間通過一種特殊的二進制協議相互交互集群信息。

??Redis Cluster 將所有數據劃分為 16384 的 slots,它比 Codis 的 1024 個槽劃分的更為精細,每個節點負責其中一部分槽位。槽位的信息存儲于每個節點中,它不像 Codis,它不需要另外的分布式存儲來存儲節點槽位信息。
??當 Redis Cluster 的客戶端來連接集群時,它也會得到一份集群的槽位配置信息。這樣當客戶端要查找某個 key 時,可以直接定位到目標節點。
??這點不同于 Codis,Codis 需要通過 Proxy 來定位目標節點,RedisCluster 是直接定位。客戶端為了可以直接定位某個具體的 key 所在的節點,它就需要緩存槽位相關信息,這樣才可以準確快速地定位到相應的節點。同時因為槽位的信息可能會存在客戶端與服務器不一致的情況,還需要糾正機制來實現槽位信息的校驗調整。
??另外,RedisCluster 的每個節點會將集群的配置信息持久化到配置文件中,所以必須確保配置文件是可寫的,而且盡量不要依靠人工修改配置文件。
??Cluster 默認會對 key 值使用 crc32 算法進行 hash 得到一個整數值,然后用這個整數值對 16384 進行取模來得到具體槽位。
??Cluster 還允許用戶強制某個 key 掛在特定槽位上,通過在 key 字符串里面嵌入 tag 標記,這就可以強制 key 所掛在的槽位等于 tag 所在的槽位。
def HASH_SLOT(key)s = key.index "{"if se = key.index "}",s+1if e && e != s+1key = key[s+1..e-1]endendcrc16(key) % 16384
end
??當客戶端向一個錯誤的節點發出了指令,該節點會發現指令的 key 所在的槽位并不歸自己管理,這時它會向客戶端發送一個特殊的跳轉指令攜帶目標操作的節點地址,告訴客戶端去連這個節點去獲取數據。
GET x
-MOVED 3999 127.0.0.1:6381
??MOVED 指令的第一個參數 3999 是 key 對應的槽位編號,后面是目標節點地址。MOVED 指令前面有一個減號,表示該指令是一個錯誤消息。
??客戶端收到 MOVED 指令后,要立即糾正本地的槽位映射表。后續所有 key 將使用新的槽位映射表。
??Redis Cluster 提供了工具 redis-trib 可以讓運維人員手動調整槽位的分配情況,它使用 Ruby 語言進行開發,通過組合各種原生的 Redis Cluster 指令來實現。這點 Codis 做的更加人性化,它不但提供了 UI 界面可以讓我們方便的遷移,還提供了自動化平衡槽位工具,無需人工干預就可以均衡集群負載。不過 Redis 官方向來的策略就是提供最小可用的工具,其它都交由社區完成。

??Redis 遷移的單位是槽,Redis 一個槽一個槽進行遷移,當一個槽正在遷移時,這個槽就處于中間過渡狀態。這個槽在原節點的狀態為 migrating,在目標節點的狀態為 importing,表示數據正在從源流向目標。
??遷移工具 redis-trib 首先會在源和目標節點設置好中間過渡狀態,然后一次性獲取源節點槽位的所有 key 列表(keysinslot 指令,可以部分獲取),再挨個 key 進行遷移。每個 key 的遷移過程是以原節點作為目標節點的「客戶端」,原節點對當前的 key 執行 dump 指令得到序列化內容,然后通過「客戶端」向目標節點發送指令 restore 攜帶序列化的內容作為參數,目標節點再進行反序列化就可以將內容恢復到目標節點的內存中,然后返回「客戶端」OK,原節點「客戶端」收到后再把當前節點的 key 刪除掉就完成了單個 key 遷移的整個過程。
??從源節點獲取內容 => 存到目標節點 => 從源節點刪除內容。
??注意這里的遷移過程是同步的,在目標節點執行 restore 指令到原節點刪除 key 之間,原節點的主線程會處于阻塞狀態,直到 key 被成功刪除。
??如果遷移過程中突然出現網絡故障,整個 slot 的遷移只進行了一半。這時兩個節點依舊處于中間過渡狀態。待下次遷移工具重新連上時,會提示用戶繼續進行遷移。
??在遷移過程中,如果每個 key 的內容都很小,migrate 指令執行會很快,它就并不會影響客戶端的正常訪問。如果 key 的內容很大,因為 migrate 指令是阻塞指令會同時導致原節點和目標節點卡頓,影響集群的穩定型。所以在集群環境下業務邏輯要盡可能避免大 key 的產生。
??在遷移過程中,客戶端訪問的流程會有很大的變化。
??首先新舊兩個節點對應的槽位都存在部分 key 數據。客戶端先嘗試訪問舊節點,如果對應的數據還在舊節點里面,那么舊節點正常處理。如果對應的數據不在舊節點里面,那么有兩種可能,要么該數據在新節點里,要么根本就不存在。舊節點不知道是哪種情況,所以它會向客戶端返回一個-ASK targetNodeAddr 的重定向指令。客戶端收到這個重定向指令后,先去目標節點執行一個不帶任何參數的 asking 指令,然后在目標節點再重新執行原先的操作指令。
??為什么需要執行一個不帶參數的 asking 指令呢?
??因為在遷移沒有完成之前,按理說這個槽位還是不歸新節點管理的,如果這個時候向目標節點發送該槽位的指令,節點是不認的,它會向客戶端返回一個-MOVED 重定向指令告訴它去源節點去執行。如此就會形成 重定向循環。asking 指令的目標就是打開目標節點的選項,告訴它下一條指令不能不理,而要當成自己的槽位來處理。
??從以上過程可以看出,遷移是會影響服務效率的,同樣的指令在正常情況下一個 ttl 就能完成,而在遷移中得 3 個 ttl 才能搞定。
??真實世界的機房網絡往往并不是風平浪靜的,它們經常會發生各種各樣的小問題。比如網絡抖動就是非常常見的一種現象,突然之間部分連接變得不可訪問,然后很快又恢復正常。
??為解決這種問題,Redis Cluster 提供了一種選項 cluster-node-timeout,表示當某個節點持續 timeout 的時間失聯時,才可以認定該節點出現故障,需要進行主從切換。如果沒有這個選項,網絡抖動會導致主從頻繁切換 (數據的重新復制)。
??還有另外一個選項 cluster-slave-validity-factor 作為倍乘系數來放大這個超時時間來寬松容錯的緊急程度。如果這個系數為零,那么主從切換是不會抗拒網絡抖動的。如果這個系數大于 1,它就成了主從切換的松弛系數。
??因為 Redis Cluster 是去中心化的,一個節點認為某個節點失聯了并不代表所有的節點都認為它失聯了。所以集群還得經過一次協商的過程,只有當大多數節點都認定了某個節點失聯了,集群才認為該節點需要進行主從切換來容錯。
??Redis 集群節點采用 Gossip 協議來廣播自己的狀態以及自己對整個集群認知的改變。比如一個節點發現某個節點失聯了 (PFail),它會將這條信息向整個集群廣播,其它節點也就可以收到這點失聯信息。如果一個節點收到了某個節點失聯的數量 (PFail Count) 已經達到了集群的大多數,就可以標記該節點為確定下線狀態 (Fail),然后向整個集群廣播,強迫其它節點也接收該節點已經下線的事實,并立即對該失聯節點進行主從切換。
??分布式應用進行邏輯處理時經常會遇到并發問題。
??比如一個操作要修改用戶的狀態,修改狀態需要先讀出用戶的狀態,在內存里進行修改,改完了再存回去。如果這樣的操作同時進行了,就會出現并發問題,因為讀取和保存狀態這兩個操作不是原子的。(Wiki 解釋:所謂 原子操作是指不會被線程調度機制打斷的操作;這種操作一旦開始,就一直運行到結束,中間不會有任何 context switch 線程切換。)

??這個時候就要使用到分布式鎖來限制程序的并發執行。Redis 分布式鎖使用非常廣泛,它是面試的重要考點之一,很多同學都知道這個知識,也大致知道分布式鎖的原理,但是具體到細節的使用上往往并不完全正確。
??分布式鎖本質上要實現的目標就是在 Redis 里面占一個“茅坑”,當別的進程也要來占時,發現已經有人蹲在那里了,就只好放棄或者稍后再試。
??占坑一般是使用 setnx(set if not exists) 指令,只允許被一個客戶端占坑。先來先占, 用完了,再調用 del 指令釋放茅坑。
簡單使用如下:
> setnx lock_codehole true # setnx 不存在 key 會添加,存在 不會覆蓋
(integer) 1
...do something critical...
> del lock_codehole
(integer) 1
??但是有個問題,如果邏輯執行到中間出現異常了,可能會導致 del 指令沒有被調用, 這樣就會陷入死鎖,鎖永遠得不到釋放。
??于是我們在拿到鎖之后,再給鎖加上一個過期時間,比如 5s,這樣即使中間出現異常也可以保證 5 秒之后鎖會自動釋放。
> setnx lock_codehole true
(integer) 1
>expire lock_codehole 5
...do something critical...
> del lock_codehole
(integer) 1
??但是以上邏輯還有問題。如果在 setnx 和 expire 之間服務器進程突然掛掉了,可能是因為機器掉電或者是被人為殺掉的,就會導致 expire 得不到執行,也會造成死鎖。
??這種問題的根源就在于 setnx 和 expire 是兩條指令而不是原子指令。如果這兩條指令可以一起執行就不會出現問題。 也許你會想到用 Redis 事務來解決。 但是這里不行, 因為 expire是依賴于 setnx 的執行結果的, 如果 setnx 沒搶到鎖, expire 是不應該執行的。 事務里沒有 if-else 分支邏輯,事務的特點是一口氣執行,要么全部執行要么一個都不執行。
??為了解決這個疑難,Redis 開源社區涌現了一堆分布式鎖的 library,專門用來解決這個問題。 實現方法極為復雜, 小白用戶一般要費很大的精力才可以搞懂。 如果你需要使用分布式鎖,意味著你不能僅僅使用 Jedis 或者 redis-py 就行了,還得引入分布式鎖的 library。

為了治理這個亂象,Redis 2.8 版本中作者加入了 set 指令的擴展參數,使得 setnx 和 expire 指令可以一起執行,徹底解決了分布式鎖的亂象。從此以后所有的第三方分布式鎖library 可以休息了。
> set lock:codehole true ex 5 nx
OK
... do something critical ...
> del lock:codehole
(integer) 1
上面這個指令就是 setnx 和 expire 組合在一起的原子指令,它就是分布式鎖的
奧義所在。
??Redis 的分布式鎖不能解決超時問題,如果在加鎖和釋放鎖之間的邏輯執行的太長,以至于超出了鎖的超時限制, 就會出現問題。 因為這時候鎖過期了, 第二個線程重新持有了這把鎖,但是緊接著第一個線程執行完了業務邏輯,就把鎖給釋放了。這樣就會陷入無限循環中。
??為了避免這個問題,Redis 分布式鎖不要用于較長時間的任務。如果真的偶爾出現了,數據出現的小波錯亂可能需要人工介入解決。
??有一個更加安全的方案使用 Redisson 客戶端。
原理:redisson 內部提供了一個監控鎖的看門狗,可以設置 lockWatchdogTimeout(監控鎖的看門狗超時時間,默認是 30s),在監控鎖被主動關閉前,會不斷的延長監控鎖的有效期,如果 redisson 客戶端節點(也就是我們的服務器)宕機,那么監控鎖時間到后自動關閉。
使用方式
??在使用 redisson 之前需要先設置pom依賴和配置 redisson 的配置文件
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.11.1</version>
</dependency>
??redisson 配置類
@Configuration
public class RedissonConfig {@Beanpublic RedissonClient configRedisson(){// 單例redis模式Config config = new Config();config.useSingleServer().setAddress("redis://127.0.0.1:6379");//設置看門狗的時間,不配置的話默認30000config.setLockWatchdogTimeout(6000);return Redisson.create(config);}
}
??業務邏輯中引入調用
@RestController
@RequestMapping("/lock")
public class LockController {@AutowiredRedissonClient redisson;@GetMapping("/test")public String lock() {RLock watchDogLock = null;try {// 這步驟只是創建了一個RLock對象,并非執行了獲取鎖的操作watchDogLock = redisson.getLock("watchDogLock");// 如果設置鎖過期時間,會導致看門狗無效watchDogLock.lock();System.out.println(Thread.currentThread().getName() + " : 獲取鎖成功");Thread.sleep(30000);System.out.println(Thread.currentThread().getName() + " : 執行業務完成");}catch (InterruptedException e) {// e.printStackTrace();}finally {if (Objects.nonNull(watchDogLock)) {try {watchDogLock.unlock();}catch (Exception e) {// e.printStackTrace();}}}return "成功";}
}
測試結果:
??在上述配置文件中設置了看門狗監控鎖的時間為 6s,每當時間減少了1/3 就會重新恢復到 6
127.0.0.1:6379> ttl watchDogLock
(integer) 6
127.0.0.1:6379> ttl watchDogLock
(integer) 5
127.0.0.1:6379> ttl watchDogLock
(integer) 6
127.0.0.1:6379> ttl watchDogLock
(integer) 5
127.0.0.1:6379> ttl watchDogLock
(integer) 4
127.0.0.1:6379> ttl watchDogLock
(integer) 6
127.0.0.1:6379> ttl watchDogLock
(integer) 5
127.0.0.1:6379> ttl watchDogLock
(integer) 4
127.0.0.1:6379> ttl watchDogLock
??redisson使用守護線程來進行鎖的續期,(守護線程的作用:當用戶線程銷毀,會和用戶線程一起銷毀。)防止程序宕機后,線程依舊不斷續命,造成死鎖!如果服務器宕機,鎖會在 6s 后自動釋放。
??redisson 守護線程的續命機制是依靠 netty 中的定時機制 HashedWheelTimer(時間輪)來完成的
??redisson 鎖在集群環境下,也是有缺陷的,它不是絕對安全的。比如在 Sentinel 集群中,主節點掛掉時,從節點會取而代之,客戶端上卻并沒有明顯感知。原先第一個客戶端在主節點中申請成功了一把鎖,但是這把鎖還沒有來得及同步到從節點,主節點突然掛掉了。然后從節點變成了主節點,這個新的節點內部沒有這個鎖,所以當另一個客戶端過來請求加鎖時,立即就批準了。這樣就會導致系統中同樣一把鎖被兩個客戶端同時持有,不安全性由此產生。

??不過這種不安全也僅僅是在主從發生 failover 的情況下才會產生,而且持續時間極短,業務系統多數情況下可以容忍。
??為了解決這個問題,Antirez 發明了 Redlock 算法,它的流程比較復雜,不過已經有了很多開源的 library 做了良好的封裝,用戶可以拿來即用,比如 redlock-py。
import redlock
addrs = [{"host": "localhost","port": 6379,"db": 0
}, {"host": "localhost","port": 6479,"db": 0
}, {"host": "localhost","port": 6579,"db": 0
}]
dlm = redlock.Redlock(addrs)
success = dlm.lock("user-lck-laoqian", 5000)
if success:print 'lock success'dlm.unlock('user-lck-laoqian')
else:print 'lock failed'
??為了使用 Redlock,需要提供多個 Redis 實例。同很多分布式算法一樣,redlock 也使用「大多數機制」。
??加鎖時,它會向過半節點發送 set(key, value, nx=True, ex=xxx) 指令,只要過半節點 set 成功,那就認為加鎖成功。釋放鎖時,需要向所有節點發送 del 指令。不過 Redlock 算法還需要考慮出錯重試、時鐘漂移等很多細節問題,同時因為 Redlock 需要向多個節點進行讀寫,意味著相比單實例 Redis 性能會下降一些。
??如果你很在乎高可用性,希望掛了一臺 redis 完全不受影響,那就應該考慮 redlock。不過代價也是有的,需要更多的 redis 實例,性能也下降了,代碼上還需要引入額外的library,運維上也需要特殊對待,這些都是需要考慮的成本,使用前請再三斟酌。
??業務使用方式:
@RestController
@RequestMapping("/lock")
public class LockController {@AutowiredRedissonClient redisson;@AutowiredRedissonClient redisson1;@GetMapping("/redLock")public String redLock() {RLock redLock = null;try {// 這步驟只是創建了一個RLock對象,并非執行了獲取鎖的操作RLock watchDogLock = redisson.getLock("watchDogLock");RLock watchDogLock1 = redisson1.getLock("watchDogLock");// watchDogLock, watchDogLock1中分別配置了2個redis單位的信息,為主、從關系redLock = redisson.getRedLock(watchDogLock, watchDogLock1);// 如果設置鎖過期時間,會導致看門狗無效redLock.lock();System.out.println(Thread.currentThread().getName() + " : 獲取鎖成功");Thread.sleep(30000);System.out.println(Thread.currentThread().getName() + " : 執行業務完成");}catch (InterruptedException e) {// e.printStackTrace();}finally {if (Objects.nonNull(redLock)) {try {redLock.unlock();}catch (Exception e) {// e.printStackTrace();}}}return "成功";}
}
??前臺請求,后臺先從緩存中取數據,取到直接返回結果,取不到時從數據庫中取,數據庫取到更新緩存,并返回結果,數據庫也沒取到,那直接返回空結果。注意,緩存是這種處理方式為前提

??描述:
? 緩存穿透是指緩存和數據庫中都沒有的數據,而用戶不斷發起請求,如發起為id為“-1”的數據或id為特別大不存在的數據。這時的用戶很可能是攻擊者,攻擊會導致數據庫壓力過大。
解決方案:
??描述:
? 緩存擊穿是指緩存中沒有但數據庫中有的單條數據(一般是緩存時間到期),這時由于并發用戶特別多,同時讀緩存沒讀到數據,又同時去數據庫去取數據,引起數據庫壓力瞬間增大,造成過大壓力
??解決方案:
??加互斥鎖偽代碼如下:
public String getData(String key) {while (true) {// 從緩存讀取數據String result = getDataForRedis(key);if(result != null) {return result;}// 嘗試獲取鎖if(tryLock(this)) {try {// 再次從緩存讀取數據,這里想想為什么?result = getDataForRedis(key);if (result != null) {return result;}// 從數據庫獲取數據result = getDataForMySql(key);if (result != null) {// 添加到 redis 緩存setDataToRedis(key, result);// 返回return result;}}finally {unLock();}}else {// 獲取鎖失敗,睡眠Thread.sleep(30);}}}
??描述:
??緩存雪崩是指緩存中數據大批量到過期時間,而查詢數據量巨大,引起數據庫壓力過大甚至 down機。和緩存擊穿不同的是,緩存擊穿指并發查同一條數據,緩存雪崩是不同數據都過期了,很多數據都查不到從而查數據庫。
?? 解決方案:
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态