本篇博客主要介绍在学习工作中运用OpenCV的场景以及对应API的介绍。关于API的详细介绍,可以查看Opencv官网提供的API:https://docs.opencv.org/4.1.2/d6/d00/tutorial_py_root.html,主要的开发语言是Python。
传统计算机视觉算法主要应用到opencv,如图像的形态学变换,边缘检测,特征提取等。在此慢慢积累相关传统计算机视觉的一些算法和操作。本博客不再进行更新了,如需了解更多的信息,可以参考我的github上面的代码,里面有较为详细的算法,地址:https://github.com/RyanCCC/ComputerVision
在介绍传统特征提取方法之前,先解释一些概念:
SIFT在不同的尺度空间上查找关键点(特征点),并计算出关键点的方向。SIFT所查找的关键点是一些非常突出,不会因光照、仿射变换和噪音等因素而变化的点,如角点、边缘点、暗区的亮点以及亮区的暗点等。
SIFT特征提取的过程:
SIFT特征提取的优点:
SIFT特征提取的缺点:
SIFT应用场景:
HOG特征提取的实质是通过计算和统计图像局部区域的梯度方向直方图来构成特征。HOG特征结合SVM分类器已经被广泛应用于图像识别中,尤其是行人检测中获得了极大的成功。
HOG特征提取的方法:
HOG特征提取特点
共同点: 都是基于图像中梯度方向直方图的特征提取方法
不同点:
LBP(Local Binary Pattern),局部二值模式是一种描述图像局部纹理的特征算子,具有旋转不变性与灰度不变性等显著优点。LBP特征描述的是一种灰度范围内的图像处理操作技术,针对的是输入源为8位或16位的灰度图像。LBP特征是高效的图像特征分析方法,经过改进与发展已经应用于多个领域之中,特别是人脸识别、表情识别、行人检测领域已经取得了成功。LBP特征将窗口中心点与邻域点的关系进行比较,重新编码形成新特征以消除对外界场景对图像的影响,因此一定程度上解决了复杂场景下(光照变换)特征描述问题。
经典LBP: 经典LBP算子窗口为3×3的正方形窗口,以窗口中心像素为阈值,将其相邻8领域像素灰度与中心像素值比较,若中心像素值小于周围像素值,则该中心像素位置被标记为1,否则为0(显然这种规则下,对于中心点大于或等于这两种情况,算法无法区分,后续经过改进引入LBP+与LBP-因子用来区分这两种情况)。图像经过这种遍历操作后,图像就被二值化了,每一个窗口中心的8邻域点都可以由8位二进制数来表示,即可产生256种LBP码,这个LBP码值可以用来反映窗口的区域纹理信息。LBP具体在生成的过程中,先将图像划分为若干个子区域,子区域窗口可根据原图像的尺寸进行调整,而不一定非得为3×3的正方形窗口。一般对于512×640的图像,子区域窗口区域选取大小为16×16。
圆形LBP: 经典LBP用正方形来描述图像的纹理特征,其缺点是难以满足不同尺寸和频率的需求。Ojala等人对经典LBP进行了改进,提出了将3×3的正方形窗口领域扩展到任意圆形领域。由于圆形LBP采样点在圆形边界上,那么必然会导致部分计算出来的采样点坐标不是整数,因此这里就需要对得到的坐标像素点值进行处理,常用的处理方法是最近邻插值或双线性插值。
python-opencv的版本是4.3.0。详情请参考我的另外一篇博客:地物分类:基于语义分割的建筑物轮廓识别。通过Unet网络对待预测的图像进行分割,提取建筑物的内容,获取建筑物内容后提取的它的轮廓线,最终成果如下图所示:

def drawContours(src_img, mask_img):if mask_img.mode is not 'RGB':mask_img = mask_img.convert('RGB')mask_img = cv2.cvtColor(np.asarray(mask_img), cv2.COLOR_BGR2GRAY)ret,binary_img=cv2.threshold(mask_img,1,255,cv2.THRESH_BINARY)# 画出轮廓contours, h= cv2.findContours(binary_img, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE) rest_img = cv2.drawContours(np.asarray(src_img),contours,-1,(255,0,255),3)return rest_img
传入的参数是原图以及预测的推理图mask,主要的流程如下:
mask_img的彩色图像转换成灰度图mask_img灰度图二值化成为黑白图像,目的是提取轮廓cv2.findContours获取轮廓线cv2.drawContours在原图上获取轮廓线cv2.threshold
因为mask图像的像素区分比较明显,而且只有两类像素,因此用简单的cv2.threshold即可。可以查看官网关于这个Api的介绍:tutorial_py_thresholding。
ret, dst = cv2.threshold(src, thresh, maxval, type)
src:输入图像,只能输入单通道图像,通常来说为灰度图dst :输出二值化图像thresh:表示阈值,在上述应用中的thresh=1maxval:当像素值超过阈值thresh所赋予的值,如例子中如果像素值超过1,则赋值为255。type:二值化操作的类型,包含以下5种类型: cv2.THRESH_BINARY; cv2.THRESH_BINARY_INV; cv2.THRESH_TRUNC; cv2.THRESH_TOZERO;cv2.THRESH_TOZERO_INV另外官方还提到一种阈值化的方式:自适应阈值二值化(cv2.adaptiveThreshold),详情可以查看官方文档的介绍。
cv2.findContours
详情请参考:tutorial_py_contour_features。官方文档中除了介绍findContours外,还详细介绍获取轮廓后如何计算轮廓的周长、包括的面积等
contours,hierarchy = cv2.findContours(image, mode, method[, contours[, hierarchy[, offset ]]])
contours:列表,每一项都是一个轮廓,存储能描述轮廓的点hierarchy:hierarchy结果,这是一个ndarray,其中的元素个数和轮廓个数相同,每个轮廓contours[i]对应4个hierarchy元素hierarchy[i][0] ~hierarchy[i][3],分别表示后一个轮廓、前一个轮廓、父轮廓、内嵌轮廓的索引编号,如果没有对应项,则该值为负数。image:一般都是二值图像mode:cv2.RETR_EXTERNAL表示只检测外轮廓;cv2.RETR_LIST检测的轮廓不建立等级关系;cv2.RETR_CCOMP建立两个等级的轮廓,上面的一层为外边界,里面的一层为内孔的边界信息。如果内孔内还有一个连通物体,这个物体的边界也在顶层;cv2.RETR_TREE建立一个等级树结构的轮廓。method:cv2.CHAIN_APPROX_NONE存储所有的轮廓点,相邻的两个点的像素位置差不超过1,即max(abs(x1−x2),abs(y2−y1)==1max(abs(x1-x2), abs(y2-y1)==1max(abs(x1−x2),abs(y2−y1)==1;cv2.CHAIN_APPROX_SIMPLE压缩水平方向,垂直方向,对角线方向的元素,只保留该方向的终点坐标,例如一个矩形轮廓只需4个点来保存轮廓信息;cv2.CHAIN_APPROX_TC89_L1,CV_CHAIN_APPROX_TC89_KCOS使用teh-Chinl chain 近似算法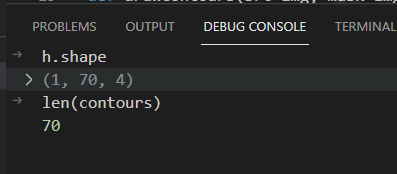
cv2.drawContours
在获取图像的轮廓后,可以使用drawContours画出轮廓线
cv2.drawContours(image, contours, contourIdx, color[, thickness[, lineType[, hierarchy[, maxLevel[, offset ]]]]])
image:指定绘制轮廓的图像contours:轮廓本身,类型为ListcontourIdx:指定绘制轮廓list中的哪一条轮廓百度一下“python opencv 车道线检测”,就有很多结果。OpenCV的车道线检测效果不太好,只是一个入门版,在这里通过这样的一个Demo了解里面涉及到的OpenCV的API,其中包括以下步骤:
import mathdef grayscale(img):return cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)def canny(img, low_threshold, high_threshold):return cv2.Canny(img, low_threshold, high_threshold)def gaussian_blur(img, kernel_size):return cv2.GaussianBlur(img, (kernel_size, kernel_size), 0)def region_of_interest(img, vertices):mask = np.zeros_like(img)if len(img.shape)>2:channel_count =img.shape[2]ignore_mask_color = (255,)*channel_countelse:ignore_mask_color = 255cv2.fillPoly(mask, vertices, ignore_mask_color)masked_image = cv2.bitwise_and(img, mask)return masked_imagedef draw_lines(img, lines, color=[255, 0, 0], thickness=10):draw_right = Truedraw_left = Trueslope_threshold = 0.5slopes = []new_lines = []for line in lines:x1, y1, x2, y2 = line[0] # line = [[x1, y1, x2, y2]]# Calculate slopeif x2 - x1 == 0.: # corner case, avoiding division by 0slope = 999. # practically infinite slopeelse:slope = (y2 - y1) / (x2 - x1)# Filter lines based on slopeif abs(slope) > slope_threshold:slopes.append(slope)new_lines.append(line)lines = new_lines# Split lines into right_lines and left_lines, representing the right and left lane lines# Right/left lane lines must have positive/negative slope, and be on the right/left half of the imageright_lines = []left_lines = []for i, line in enumerate(lines):x1, y1, x2, y2 = line[0]img_x_center = img.shape[1] / 2 # x coordinate of center of imageif slopes[i] > 0 and x1 > img_x_center and x2 > img_x_center:right_lines.append(line)elif slopes[i] < 0 and x1 < img_x_center and x2 < img_x_center:left_lines.append(line)# Run linear regression to find best fit line for right and left lane lines# Right lane linesright_lines_x = []right_lines_y = []for line in right_lines:x1, y1, x2, y2 = line[0]right_lines_x.append(x1)right_lines_x.append(x2)right_lines_y.append(y1)right_lines_y.append(y2)if len(right_lines_x) > 0:right_m, right_b = np.polyfit(right_lines_x, right_lines_y, 1) # y = m*x + belse:right_m, right_b = 1, 1draw_right = False# Left lane linesleft_lines_x = []left_lines_y = []for line in left_lines:x1, y1, x2, y2 = line[0]left_lines_x.append(x1)left_lines_x.append(x2)left_lines_y.append(y1)left_lines_y.append(y2)if len(left_lines_x) > 0:left_m, left_b = np.polyfit(left_lines_x, left_lines_y, 1) # y = m*x + belse:left_m, left_b = 1, 1draw_left = False# Find 2 end points for right and left lines, used for drawing the line# y = m*x + b --> x = (y - b)/my1 = img.shape[0]y2 = img.shape[0] * (1 - trap_height)right_x1 = (y1 - right_b) / right_mright_x2 = (y2 - right_b) / right_mleft_x1 = (y1 - left_b) / left_mleft_x2 = (y2 - left_b) / left_m# Convert calculated end points from float to inty1 = int(y1)y2 = int(y2)right_x1 = int(right_x1)right_x2 = int(right_x2)left_x1 = int(left_x1)left_x2 = int(left_x2)# Draw the right and left lines on imageif draw_right:cv2.line(img, (right_x1, y1), (right_x2, y2), color, thickness)if draw_left:cv2.line(img, (left_x1, y1), (left_x2, y2), color, thickness)def hough_lines(img, rho, theta, threshold, min_line_len, max_line_gap):"""`img` should be the output of a Canny transform.Returns an image with hough lines drawn."""lines = cv2.HoughLinesP(img, rho, theta, threshold, np.array([]), minLineLength=min_line_len, maxLineGap=max_line_gap)#line_img = np.zeros(img.shape, dtype=np.uint8) # this produces single-channel (grayscale) imageline_img = np.zeros((*img.shape, 3), dtype=np.uint8) # 3-channel RGB imagedraw_lines(line_img, lines)#draw_lines_debug2(line_img, lines)return line_img# Python 3 has support for cool math symbols.def weighted_img(img, initial_img, α=0.8, β=1., λ=0.):"""`img` is the output of the hough_lines(), An image with lines drawn on it.Should be a blank image (all black) with lines drawn on it.`initial_img` should be the image before any processing.The result image is computed as follows:initial_img * α + img * β + λNOTE: initial_img and img must be the same shape!"""return cv2.addWeighted(initial_img, α, img, β, λ)def filter_colors(image):"""Filter the image to include only yellow and white pixels"""# Filter white pixelswhite_threshold = 200lower_white = np.array([white_threshold, white_threshold, white_threshold])upper_white = np.array([255, 255, 255])white_mask = cv2.inRange(image, lower_white, upper_white)white_image = cv2.bitwise_and(image, image, mask=white_mask)# Filter yellow pixelshsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)lower_yellow = np.array([90,100,100])upper_yellow = np.array([110,255,255])yellow_mask = cv2.inRange(hsv, lower_yellow, upper_yellow)yellow_image = cv2.bitwise_and(image, image, mask=yellow_mask)# Combine the two above imagesimage2 = cv2.addWeighted(white_image, 1., yellow_image, 1., 0.)return image2def annotate_image(image_in):""" Given an image Numpy array, return the annotated image as a Numpy array """# Only keep white and yellow pixels in the image, all other pixels become blackimage = filter_colors(image_in)# Read in and grayscale the image#image = (image*255).astype('uint8') # this step is unnecessary nowgray = grayscale(image)# Apply Gaussian smoothingblur_gray = gaussian_blur(gray, kernel_size)# Apply Canny Edge Detectoredges = canny(blur_gray, low_threshold, high_threshold)# Create masked edges using trapezoid-shaped region-of-interestimshape = image.shapevertices = np.array([[\((imshape[1] * (1 - trap_bottom_width)) // 2, imshape[0]),\((imshape[1] * (1 - trap_top_width)) // 2, imshape[0] - imshape[0] * trap_height),\(imshape[1] - (imshape[1] * (1 - trap_top_width)) // 2, imshape[0] - imshape[0] * trap_height),\(imshape[1] - (imshape[1] * (1 - trap_bottom_width)) // 2, imshape[0])]]\, dtype=np.int32)masked_edges = region_of_interest(edges, vertices)# Run Hough on edge detected imageline_image = hough_lines(masked_edges, rho, theta, threshold, min_line_length, max_line_gap)# Draw lane lines on the original imageinitial_image = image_in.astype('uint8')annotated_image = weighted_img(line_image, initial_image)return annotated_image
# Display an example image
annotated_image = annotate_image(mpimage.imread(os.path.join(file_dir, 'solidYellowLeft.jpg')))
plt.imshow(annotated_image)
from PIL import Image
res = Image.fromarray(annotated_image)
res.save('1.png')
cv2.Canny
cv2.Canny(image, # 输入原图(必须为单通道图)threshold1, threshold2, # 较大的阈值2用于检测图像中明显的边缘[, edges[, apertureSize[, # apertureSize:Sobel算子的大小L2gradient ]]]) # 参数(布尔值):# true: 使用更精确的L2范数进行计算(即两个方向的倒数的平方和再开放),# false:使用L1范数(直接将两个方向导数的绝对值相加)。
一般的canny检测包括以下4个步骤:
详情请参考:https://docs.opencv.org/3.0-beta/doc/py_tutorials/py_imgproc/py_canny/py_canny.html#canny
cv2.GaussianBlur
该函数主要是消除高斯噪声,广泛应用于图像处理的去除噪声的过程。
cv2.GaussianBlur(img, (kernel_size, kernel_size), 0)
cv2.fillPoly
该函数是用来填充任意形状的图形,可以用来绘制多边形,也可以填充线条
cv2.fillPoly(img, [list], color)
cv2.HoughLinesP
统计概率霍夫线变换函数
HoughLinesP(image, rho, theta, threshold[, lines[, minLineLength[, maxLineGap]]]) -> lines
image参数表示边缘检测的输出图像,该图像为单通道8位二进制图像。
rho参数表示参数极径rrr以像素值为单位的分辨率,这里一般使用 1 像素。
theta参数表示参数极角θ\thetaθ以弧度为单位的分辨率,这里使用 1度。
threshold参数表示检测一条直线所需最少的曲线交点。
lines参数表示储存着检测到的直线的参数对(xstart,ystart,xend,yend)(x_{start}, y_{start}, x_{end}, y_{end})(xstart,ystart,xend,yend)的容器,也就是线段两个端点的坐标。
minLineLength参数表示能组成一条直线的最少点的数量,点数量不足的直线将被抛弃。
maxLineGap参数表示能被认为在一条直线上的亮点的最大距离。
霍夫变换的解读可以参考:一文解读经典霍夫曼变换
cv2.inRangecv2.inRange(hsv, lower_red, upper_red)
hsv:原图。lower_red:图像中低于这个lower_red的值,图像值变为0。upper_red:图像中高于这个upper_red的值,图像值变为0。图像的开运算与闭运算是图像形态学两种基础的用法,在了解开运算与闭运算的过程需要了解什么是腐蚀以及膨胀,因为开运算与闭运算是腐蚀与膨胀的组合使用。腐蚀膨胀示意图如下:

膨胀

腐蚀

开运算
开运算是先进行腐蚀再进行膨胀的运算,图像被腐蚀后去除了噪声,同时也压缩了前景,再进行膨胀,使得压缩的前景恢复原状。因此开运算能够除去孤立的小点、毛刺和小桥,而总的位置和形状不变。

闭运算
闭运算与开运算相反,闭运算是先膨胀后腐蚀,有助于去除前景物体内部的小孔,或前景上的小黑点。

# 读取图片
source = cv.imread("demo_noise_white.jpg", cv.IMREAD_GRAYSCALE)# 设置卷积核
kernel = np.ones((5, 5),np.uint8)# 图像腐蚀
erode_img = cv.erode(source, kernel)# 图像膨胀
dilate_result = cv.dilate(erode_img, kernel)
或者
dst = cv.morphologyEx(src, cv.MORPH_OPEN, kernel)
# 读取图片
source = cv.imread("demo_noise_black.jpg", cv.IMREAD_GRAYSCALE)# 设置卷积核
kernel = np.ones((5, 5),np.uint8)# 图像膨胀
dilate_result = cv.dilate(source, kernel)# 图像腐蚀
erode_img = cv.erode(dilate_result, kernel)
或者
dst = cv.morphologyEx(source, cv.MORPH_CLOSE, kernel)
在这里不多说明了,比较简单,主要是要学会运用,了解什么情况使用开运算以及什么情况下使用闭运算
在使用labelme标注实例分割的数据集的时候,过程非常的痛苦,大概3到5分钟一张图。为了提升一点点的效率,使用已经训练好的模型进行预处理,然后再人工标注。使用模型的进行预处理的思路是模型识别出mask,然后通过opencv findcontours画出轮廓线,将轮廓线保存成labelme标准的json格式数据。
大体代码跟应用一差不多,成品结果是:

这个结果有个缺点是,点的数量太多了,需要进行采样,采样的代码如下:
# 根据轮廓线画出近似轮廓
epsilon = 0.01*cv2.arcLength(contours[0], True)
approx = cv2.approxPolyDP(contours[0], epsilon, True)
cv2.polylines(masked_image, [approx], 1, (color[0] * 255,color[1] * 255,color[2] * 255), 2)
shapes.append((label, [approx]))
最终的结果如下图所示:

可以点相对于上图已经有了优化。
cv2.arcLength
该函数主要是获取轮廓周长,参数包括curve:轮廓线,即contours[0]以及是否闭合标志:closed?
cv2.approxPolyDP
Creating Bounding boxes and circles for contours。
本模块主要是说明一些基础的图像应用,比如:图像锐化、噪声以及滤波
'''
python opencv 实现图像锐化
'''
def cv_filter2d(img_path):src = cv2.imread(img_path)kernel = np.array([[0, -1, 0],[-1, 5, -1],[0, -1, 0]])dst = cv2.filter2D(src, -1, kernel)cv2.imshow('origin', src)cv2.imshow('dst', dst)basename = os.path.basename(img_path)save_path = os.path.join('./result', basename)cv2.waitKey(0)cv2.destroyAllWindows()cv2.imwrite(save_path, dst)
skimage模块img = cv2.imread(img_path)
noise_img = skimage.util.random_noise(img, mode='s&p', amount=0.1)
cv2.imshow('noise_img', noise_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
img = cv2.imread(img_path)
blur1 = cv2.blur(img, (5, 5))
noise_img = skimage.util.random_noise(img)
blur2 = cv2.blur(noise_img, (5, 5))
sp_noise_img = skimage.util.random_noise(img, 's&p', amount=0.1)
blur3 = cv2.blur(sp_noise_img, (5, 5))cv2.imshow('1', img)
cv2.imshow('2', blur1)
cv2.imshow('3', noise_img)
cv2.imshow('4', blur2)
cv2.imshow('5', sp_noise_img)
cv2.imshow('6', blur3)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.filter2Ddst = cv2.filter2D(src, ddepth, kernel[, dst[, anchor[, delta[, borderType]]]])
参数:
更多的Demo可以参考以下的博客:Python-OpenCV中的filter2D()函数
skimage.util.random_noiseskimage.util.random_noise(image, mode=‘gaussian’, seed=None, clip=True, **kwargs)
参数
cv2.blur在网上进行爬虫的时候,爬取的图像周围都存在白边,如下图所示。为了提高数据的质量,需要把白边去掉:

去除白边的基本思路有两个:

代码如下:
for item in tqdm(glob(pattern)):img = cv2.imread(item)# 对图像进行二值化,先转换成灰度图gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)ret, binary_img = cv2.threshold(gray_img, 128, 255, cv2.THRESH_BINARY)canny_img = cv2.Canny(gray_img, 50, 150)showImg(canny_img)# 遍历像素0:黑色,255为白色pixels_x = []pixels_y = []width, height = canny_img.shapefor i in range(width):for j in range(height):if canny_img[i][j] == 255:pixels_x.append(i)pixels_y.append(j)x_min = min(pixels_x)x_max = max(pixels_x)y_min = min(pixels_y)y_max = max(pixels_y)ROI = img[x_min:x_max, y_min:y_max]showImg(ROI)cv2.imwrite(item, ROI)
最终效果:

在此将学习如何从图像中提取含有条形码的区域,通过利用形态算子的扩张和侵蚀以及开运算,闭运算和黑帽算子的组合,对条形码区域进行分割。效果如下图所示:

首先对图像进行二值化处理,这样可以通过阈值的设定来提取出感兴趣的部分。使用黑帽运算符,增加较暗的图像元素。可以使用简单的全局阈值安全地对图像进行二值化处理。黑帽运算符可以使用非常低的阈值,而不必过多地关注噪声。在应用blackhat时,使用的内核会更加重视垂直图像像素。内核具有固定的大小,因此可以缩放图像,提高性能。
#riscalatura dell'immagine
scale = 800.0 / im.shape[1]
im = cv2.resize(im, (int(im.shape[1] * scale), int(im.shape[0] * scale)))#blackhat
kernel = np.ones((1, 3), np.uint8)
im = cv2.morphologyEx(im, cv2.MORPH_BLACKHAT, kernel, anchor=(1, 0))#sogliatura
thresh, im = cv2.threshold(im, 10, 255, cv2.THRESH_BINARY)

膨胀和闭合的这种组合在测试图像上效果很好,但可能无法在其他图像上达到相同的效果。这没有关系,大家可以尝试改变参数和运算符的组合,直到对结果满意为止。膨胀+闭运算最后的预处理步骤是应用具有很大内核的开运算符,以删除太少而无法适合条形码形状的元素。

kernel = np.ones((21, 35), np.uint8)
im = cv2.morphologyEx(im, cv2.MORPH_OPEN, kernel, iterations=1)
import cv2
import matplotlib.pyplot as plt
import numpy as npim = cv2.imread(r'img\barcodes.jpg', cv2.IMREAD_GRAYSCALE)
im_out = cv2.imread(r'img\barcodes.jpg')#riscalatura dell'immagine
scale = 800.0 / im.shape[1]
im = cv2.resize(im, (int(im.shape[1] * scale), int(im.shape[0] * scale)))#blackhat
kernel = np.ones((1, 3), np.uint8)
im = cv2.morphologyEx(im, cv2.MORPH_BLACKHAT, kernel, anchor=(1, 0))#sogliatura
thresh, im = cv2.threshold(im, 10, 255, cv2.THRESH_BINARY)#operazioni morfologiche
kernel = np.ones((1, 5), np.uint8)
im = cv2.morphologyEx(im, cv2.MORPH_DILATE, kernel, anchor=(2, 0), iterations=2) #dilatazione
im = cv2.morphologyEx(im, cv2.MORPH_CLOSE, kernel, anchor=(2, 0), iterations=2) #chiusurakernel = np.ones((21, 35), np.uint8)
im = cv2.morphologyEx(im, cv2.MORPH_OPEN, kernel, iterations=1)#estrazione dei componenti connessi
contours, hierarchy = cv2.findContours(im, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)unscale = 1.0 / scale
if contours != None:for contour in contours:# se l'area non è grande a sufficienza la salto if cv2.contourArea(contour) <= 2000:continue#estraggo il rettangolo di area minima (in formato (centro_x, centro_y), (width, height), angolo)rect = cv2.minAreaRect(contour)#l'effetto della riscalatura iniziale deve essere eliminato dalle coordinate rilevaterect = \((int(rect[0][0] * unscale), int(rect[0][1] * unscale)), \(int(rect[1][0] * unscale), int(rect[1][1] * unscale)), \rect[2])#disegno il tutto sull'immagine originalebox = np.int0(cv2.cv.BoxPoints(rect))cv2.drawContours(im_out, [box], 0, (0, 255, 0), thickness = 2)plt.imshow(im_out)
#scrittura dell' immagine finale
cv2.imwrite(r'img\out.png', im_out)
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态