由于MAML作者提供的源码比较混乱,而且是由tensorflow写成。所以我写了一篇用Pytorch复现MAML的博客:MAML模型无关的元学习代码完整复现(Pytorch版)。那篇博客中的复现细节已经很详尽了,但是在omniglot数据集上的准确率只有0.92,考虑到omniglot算是比较简单的数据集了,因此0.92的准确率实在是太低了。
因此,我后来又对模型和数据的读取方法进行了一些调整,最近的实验表明在5-way-1-shot任务上,我的复现准确率已经达到了0.972,算是基本匹配上了作者在论文中给出的准确率区间。
在这篇文章中,我将总结一下我复现MAML时的一些经验和教训以及对原来代码的更改。
我之前的数据读取方式是将omniglot中images_backgroud和images_evaluation这两个文件夹中的数据一次性读取出来,然后再对数据集进行划分。
img_list = np.load(os.path.join(root_dir, 'omniglot.npy')) # (1623, 20, 1, 28, 28)
x_train = img_list[:1200]
x_test = img_list[1200:]
这一次我使用通用的数据划分方法,即:images_backgroud中的数据作为训练数据,images_evaluation中的数据作为测试数据。
img_list_train = np.load(os.path.join(root_dir, 'omniglot_train.npy')) # (964, 20, 1, 28, 28)
img_list_test = np.load(os.path.join(root_dir, 'omniglot_test.npy')) # (659, 20, 1, 28, 28)x_train = img_list_train
x_test = img_list_test
具体代码见我的github。
原来的模型卷积层的padding为2,stride也为2;我将它们修改为1之后,实验结果直接从0.92提升到了0.975。由此可见模型架构的微小调整也会严重影响模型的性能。大家平时在做实验时应该注意一下。
原来的模型架构为:
# self.conv = nn.Sequential(
# nn.Conv2d(in_channels = 1, out_channels = 64, kernel_size = (3,3), padding = 2, stride = 2),
# nn.BatchNorm2d(64),
# nn.ReLU(),
# nn.MaxPool2d(2),# nn.Conv2d(in_channels = 64, out_channels = 64, kernel_size = (3,3), padding = 2, stride = 2),
# nn.BatchNorm2d(64),
# nn.ReLU(),
# nn.MaxPool2d(2),# nn.Conv2d(in_channels = 64, out_channels = 64, kernel_size = (3,3), padding = 2, stride = 2),
# nn.BatchNorm2d(64),
# nn.ReLU(),
# nn.MaxPool2d(2), # nn.Conv2d(in_channels = 64, out_channels = 64, kernel_size = (3,3), padding = 2, stride = 2),
# nn.BatchNorm2d(64),
# nn.ReLU(),
# nn.MaxPool2d(2), # FlattenLayer(),
# nn.Linear(64,5)
# )
修改后的模型架构为:
# self.conv = nn.Sequential(
# nn.Conv2d(in_channels = 1, out_channels = 64, kernel_size = (3,3), padding = 1, stride = 1),
# nn.BatchNorm2d(64),
# nn.ReLU(),
# nn.MaxPool2d(2),# nn.Conv2d(in_channels = 64, out_channels = 64, kernel_size = (3,3), padding = 1, stride = 1),
# nn.BatchNorm2d(64),
# nn.ReLU(),
# nn.MaxPool2d(2),# nn.Conv2d(in_channels = 64, out_channels = 64, kernel_size = (3,3), padding = 1, stride = 1),
# nn.BatchNorm2d(64),
# nn.ReLU(),
# nn.MaxPool2d(2), # nn.Conv2d(in_channels = 64, out_channels = 64, kernel_size = (3,3), padding = 1, stride = 1),
# nn.BatchNorm2d(64),
# nn.ReLU(),
# nn.MaxPool2d(2), # FlattenLayer(),
# nn.Linear(64,5)
# )
在进行20-way-1-shot的实验时,发现用原来的代码将会消耗大量的资源。我修改了一下原来的代码,在不需要记录梯度的位置加上"with torch.no_grad()",从而将计算资源的需求降到了原来的1/5.
原来的代码为:
for k in range(1, self.update_step):y_hat = self.net(x_spt[i], params = fast_weights, bn_training=True)loss = F.cross_entropy(y_hat, y_spt[i])grad = torch.autograd.grad(loss, fast_weights)tuples = zip(grad, fast_weights) fast_weights = list(map(lambda p: p[1] - self.base_lr * p[0], tuples))y_hat = self.net(x_qry[i], params = fast_weights, bn_training = True)loss_qry = F.cross_entropy(y_hat, y_qry[i])loss_list_qry[k+1] += loss_qrywith torch.no_grad():pred_qry = F.softmax(y_hat,dim=1).argmax(dim=1)correct = torch.eq(pred_qry, y_qry[i]).sum().item()correct_list[k+1] += correct
修改后的代码为:
for k in range(1, self.update_step):y_hat = self.net(x_spt[i], params = fast_weights, bn_training=True)loss = F.cross_entropy(y_hat, y_spt[i])grad = torch.autograd.grad(loss, fast_weights)tuples = zip(grad, fast_weights) fast_weights = list(map(lambda p: p[1] - self.base_lr * p[0], tuples))if k < self.update_step - 1:with torch.no_grad(): y_hat = self.net(x_qry[i], params = fast_weights, bn_training = True)loss_qry = F.cross_entropy(y_hat, y_qry[i])loss_list_qry[k+1] += loss_qryelse:y_hat = self.net(x_qry[i], params = fast_weights, bn_training = True)loss_qry = F.cross_entropy(y_hat, y_qry[i])loss_list_qry[k+1] += loss_qry with torch.no_grad():pred_qry = F.softmax(y_hat,dim=1).argmax(dim=1)correct = torch.eq(pred_qry, y_qry[i]).sum().item()correct_list[k+1] += correct
2020/5/10更新:
Reptile这篇论文中说,MAML的实验使用到了transductive Learning的实验设定。关于transductive Learning你可以理解成MAML作者汇报的是训练中query集的结果,而不是我们通常意义的测试集中query集的结果。
这个图表来自Reptile的那篇论文。

以下是原文:
我在复现这个实验的过程中,在测试集的query集中的最好结果也只有0.843。但是作者宣称她取得了0.95的实验结果,但是作者的源码中并没有给出20-way-1-shot的实验结果或者logs。
我找到了另一个网友(github账号名:katerkelly)的复现代码,这个人宣称他复现出来的结果是0.92。
20-way 1-shot training, best performance 92%
但是我实际运行以及查看了他的代码后发现,他报告的其实是训练集中query集的结果,而不是测试集中query集的结果。我们都知道在元学习中有support集和query集两者集合,其中:
而那位网友报告的是训练集中support集的结果,真正的实验结果应该是测试集中support集的实验结果,也就是0.83。
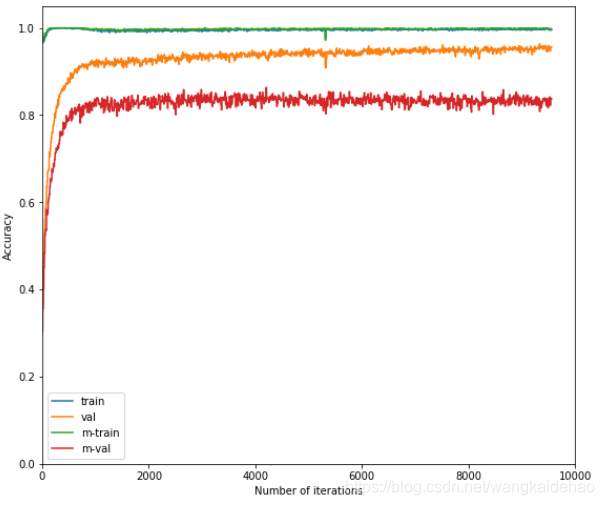
你可以查看那位网友给出的实验结果展示图(下图)。中间那条橙黄色的线是0.92左右,那位网友报告的也是橙黄色这条线的结果,但是实际的实验结果应该是下面这条红色的线。也就是0.83左右,跟我得出的实验结果比较吻合。
有意思的是,MAML作者声称她的实验结果实0.95,而我自己复现的结果中,在测试集的support集上的结果也是0.95-0.96。为了跑出0.9以上的实验结果,我已经做了好几天的实验了,模型架构和超参数改动了几十次,最好的结果还是只有0.843。如果哪位网友能够复现出0.9以上的实验结果,麻烦告诉我一下。
以下展示在60000轮epoch中,query集的测试集中出现的最好结果:
20 way 1 shot 4 batch meta_lr = 0.0002, base_lr = 0.1 : acc: 0.84
20 way 1 shot 8 batch meta_lr = 0.0001, base_lr = 0.1 : acc: 0.835
20 way 1 shot 8 batch meta_lr = 0.0001, base_lr = 0.1 : acc: 0.843
20 way 1 shot 8 batch meta_lr = 0.0005, base_lr = 0.3 : acc: 0.79
20 way 1 shot 8 batch meta_lr = 0.001, base_lr = 0.1 : acc: 0.82
20 way 1 shot 8 batch meta_lr = 0.001, base_lr = 0.2 : acc: 0.785
5 way 1 shot 4 batch 10 range meta_lr = 0.001, base_lr = 0.1 : acc: 0.96
5 way 1 shot 8 batch 10 range meta_lr = 0.001, base_lr = 0.1 : acc: 0.972
5 way 1 shot 16 batch 10 range meta_lr = 0.001, base_lr = 0.1 : acc: 0.969
5 way 1 shot 32 batch 10 range meta_lr = 0.001, base_lr = 0.1 : acc: 0.975
自己想要复现的朋友,可以参考一下我的实验结果,免得继续做无用功。
你可以在我的github上找到我的全部代码(miguealanmath)。喜欢的朋友可以点下小星星。
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态