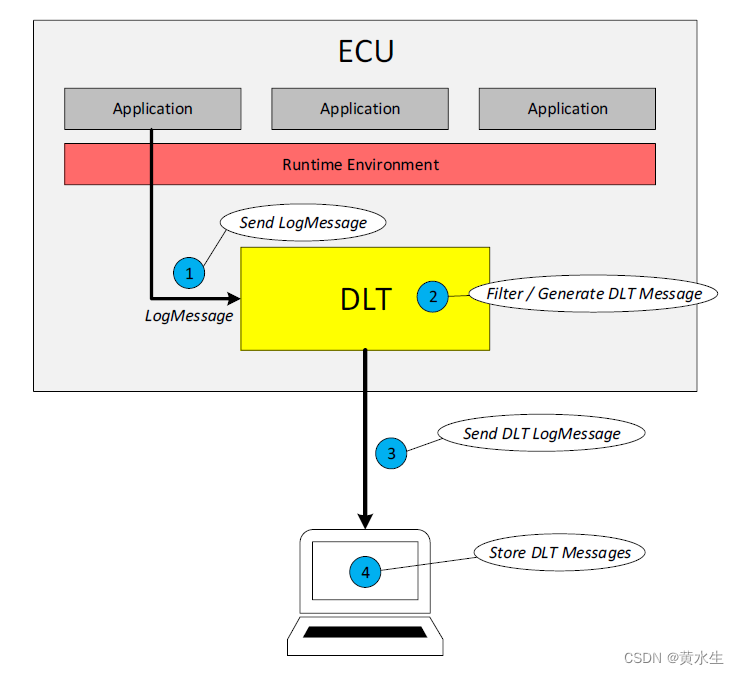
job.waitForCompletion(true);进入源码
submit()-> connect();连接,客户端获取服务端的代理对象
connect()->new Cluster(getConfiguration());
Cluster(jobTrackAddr,conf)->initialize->clientProtocol RPC通信versionID
submit() ->submitter.submitJobInternal(Job.this, cluster):
checkSpecs(job);检查路径
copyAndConfigureFiles(job, submitJobDir);拷贝并且将文件写入到hfds
printTokens(jobId, job.getCredentials());
submitJob(jobId, submitJobDir.toString(), job.getCredentials())提交job
int maps = writeSplits(job, submitJobDir);job分割切片
writeSplits()-》maps = writeNewSplits(job, jobSubmitDir);-》 List splits = input.getSplits(job);//FileInputFormat获取切片
List getSplits(JobContext job)-》long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
getMinSplitSize(job)获取mapreduce.input.fileinputformat.split.minsize的值(hadoop-mapreduce-client-core-》mapred-default.xml)
List getSplits(JobContext job)-》long minSize 最终为1
List getSplits(JobContext job)-》long maxSize = getMaxSplitSize(job);-》在mapred-default.xml没有获取到值,得long的最大值
返切片文件列表splits